The Engine Behind AI Agents
Introduction
Series: My Journey to Building AI Agents
Audience: Senior Full Stack Developers · Solution Architects · Tech Leads
Here's something that caught me off guard: the transformer architecture that powers every modern LLM was introduced in a single 2017 Google paper titled "Attention Is All You Need". Eight researchers, one architecture, and now it's running everything from chatbots to code assistants. I wanted to understand what makes this thing tick before I start building agents on top of it.
If you're building AI agents without understanding how LLMs process information, you're essentially debugging a black box. I've realized that knowing how tokens flow through attention layers, why context windows matter, and what causes hallucinations gives me the mental models I need to design better systems. This isn't academic curiosity, it's practical foundation work.
In this article, I'm exploring four core concepts: how transformers process text, what tokenization actually does, why attention mechanisms are the key innovation, and what's really going on when models hallucinate. Let's figure this out together.
The Transformer Architecture
The transformer is the neural network architecture that powers GPT, Claude, and every major LLM. Before transformers, we had recurrent neural networks (RNNs) that processed text sequentially, one word at a time. The breakthrough? Transformers process all tokens in parallel, using attention to determine which parts of the input matter for each output.
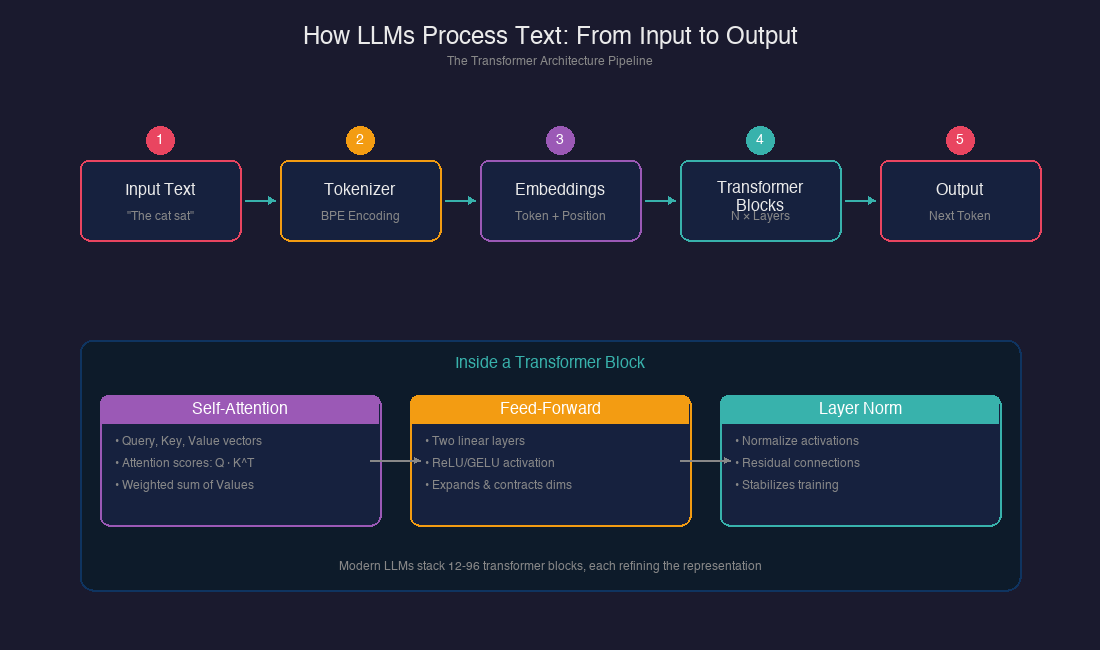
Here's the basic structure I've mapped out:
┌─────────────────────────────────────────────────────────────────┐
│ TRANSFORMER ARCHITECTURE │
├─────────────────────────────────────────────────────────────────┤
│ │
│ INPUT: "The cat sat on the mat" │
│ │ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ TOKENIZATION │ → Split into tokens + IDs │
│ └──────────┬──────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ EMBEDDING │ → Convert tokens to vectors │
│ │ + POSITIONAL INFO │ → Add position awareness │
│ └──────────┬──────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ TRANSFORMER BLOCK │ ──┐ │
│ │ • Self-Attention │ │ │
│ │ • Feed-Forward │ │ Repeat N times │
│ │ • Normalization │ │ (12-96 blocks) │
│ └──────────┬──────────┘ ──┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ OUTPUT LAYER │ → Probability over vocabulary │
│ └──────────┬──────────┘ │
│ │ │
│ ▼ │
│ OUTPUT: Next token prediction │
│ │
└─────────────────────────────────────────────────────────────────┘
Modern LLMs like GPT and Claude use a decoder-only variant of this architecture. They discard the encoder entirely, relying solely on decoder blocks with masked self-attention. This masking ensures the model can only attend to tokens it has already seen—critical for generating text one token at a time.
| Model | Architecture | Blocks | Parameters |
|---|---|---|---|
| GPT-2 Small | Decoder-only | 12 | 124M |
| GPT-3 | Decoder-only | 96 | 175B |
| Claude 3 | Decoder-only (dense) | Not disclosed | Not disclosed |
| GPT-4 | Decoder-only | Not disclosed | Rumored 1.7T (MoE) |
What's interesting: Anthropic has noted that Claude models use a dense transformer rather than a mixture-of-experts, focusing on extensive fine-tuning rather than raw parameter count.
Tokenization: How Text Becomes Numbers
Before a transformer can process text, it needs to convert words into numbers. This is tokenization, and honestly? It's messier than I expected.
Modern LLMs use Byte Pair Encoding (BPE), which creates tokens representing word fragments rather than whole words. GPT-2 introduced a 50,000-token vocabulary. By GPT-4, this expanded to over 100,000 tokens, and GPT-4o uses roughly 200,000 tokens.
Here's how tokenization affects what we see:
| Input Text | Tokens | Count |
|---|---|---|
| "Hello" | ["Hello"] | 1 |
| "tokenization" | ["token", "ization"] | 2 |
| "LLM" | ["L", "L", "M"] | 3 |
| "anthropic" | ["anthrop", "ic"] | 2 |
This fragmentation has real implications for agents:
- Cost calculation: APIs charge per token, not per word. A 1,000-word document might be 1,300+ tokens.
- Context limits: Your 128K context window is 128K tokens, not words.
- Edge cases: Unusual words or code syntax can consume more tokens than expected.
The tokenizer is essentially the model's sensory system. Anything the model "sees" passes through this lens first.
Attention: The Core Innovation
Self-attention is the mechanism that lets transformers understand relationships between tokens—regardless of their distance in the sequence. This is what the "Attention Is All You Need" paper actually introduced.
Self-Attention Mechanism: How Tokens Relate to Each Other

I learn best by seeing things in action, so instead of a static diagram, here's an interactive visualization of the Transformer self-attention mechanism (that's what I understood from my research). Click any token and watch how it "looks at" the rest of the sentence.
Self-Attention Mechanism
Click any token — see how it attends to the rest of the sequence
↑ Click any token above to explore its attention pattern
softmax( Q · Kᵀ / √d_k ) · V
weights sum to 1 per token
Try clicking "sat", you'll notice it leans heavily on "cat" because a verb naturally looks for its subject. Then click "on" and watch it pull toward "mat", which makes sense since "on" is describing where the mat is.
What's actually happening here:
Each arc's thickness shows how much one word "borrows" meaning from another. The thicker the line, the more attention it's paying. That's really the core idea, every word doesn't just mean what it means in isolation, it means something in relation to the words around it.
A couple of things I found interesting when I dug into this:
Every word attends to itself a little, it never completely forgets what it is. And attention is asymmetric, meaning "cat" looking at "sat" is not the same as "sat" looking at "cat" which honestly blew my mind a little.
There's a formula behind all of this that explains exactly how these weights are calculated, but I'll be honest, the math is way beyond me. What matters is the intuition: every token is constantly asking "who should I be paying attention to right now?" and that's what this visualization shows.
The Old Way Was Terrible
Before this, AI read text like reading with your finger, one word at a time, left to right. By the time it got to the end of a long sentence, it had basically forgotten the beginning. Super slow, super forgetful.
The New Way: Ask, Answer, Share
For every single word, the AI does three things simultaneously:
- Query (Q) — "What am I looking for?" → Like asking "hey, who did the sitting?"
- Key (K) — "What do I contain?" → Each word raises its hand saying "I'm a subject!" or "I'm an action!"
- Value (V) — "What's my actual info?" → The real meaning each word carries
The AI then scores how much every word should pay attention to every other word. In the example, "sat" scores "cat" really high (0.6) because they're obviously connected. It barely cares about "the" or "on."
Why Is This Genius?
- It works across long distances. Even if "cat" and "sat" were 500 words apart, attention still connects them.
- It runs in parallel. All words get processed at the same time, not one-by-one. Way faster.
- Multiple "heads" = multiple perspectives. Think of it like having 12 friends read the same sentence — one notices grammar, one notices emotion, one notices who's doing what. They all share notes at the end.
One thing that stood out from my research: attention has a quadratic cost. Processing 100K tokens doesn't cost 10x more than 10K—it can cost 50x more due to the attention mechanism's complexity. This explains why longer context windows come with significant latency and cost tradeoffs.
Context Windows: The Model's Working Memory
The context window is the maximum number of tokens an LLM can process simultaneously. Think of it as the model's working memory—everything outside this window simply doesn't exist for the model.
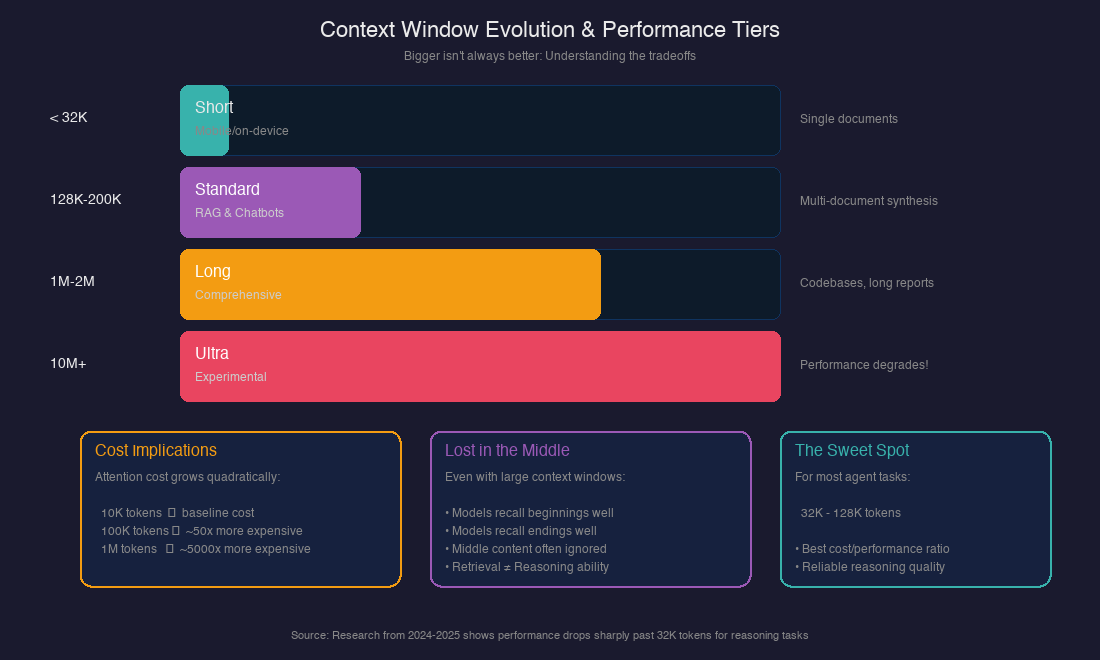
Here's the evolution I've tracked:
| Year | Typical Context | Example Models |
|---|---|---|
| 2023 | 4K-8K tokens | GPT-3.5, early Claude |
| 2024 | 32K-128K tokens | GPT-4 Turbo, Claude 3 |
| 2025 | 200K-1M+ tokens | Claude 3.5+, Gemini 1.5 |
But here's what surprised me: larger context windows don't automatically mean better reasoning. Research shows a phenomenon called "attention dilution"—when context grows too large, models struggle to find and apply relevant information even if they can technically retrieve it.
From what I've read, this creates a practical hierarchy:
CONTEXT WINDOW TIERS
═══════════════════════════════════════
< 32K tokens │ Mobile/on-device, fast inference
│ Good for: Single document analysis
───────────────┼───────────────────────────────────
128K-200K │ Standard for RAG and chatbots
│ Good for: Multi-document synthesis
───────────────┼───────────────────────────────────
1M-2M tokens │ Comprehensive analysis
│ Good for: Entire codebases, long reports
───────────────┼───────────────────────────────────
10M+ tokens │ Frontier / experimental
│ Warning: Performance degrades significantly
For agent design, this matters because agents often need to accumulate context over multiple steps. Understanding these limits helps me design systems that stay within the "golden zone" where models perform reliably.
Why LLMs Hallucinate
This section genuinely surprised me. I assumed hallucinations were bugs to be fixed—turns out, they're closer to systemic incentive problems.
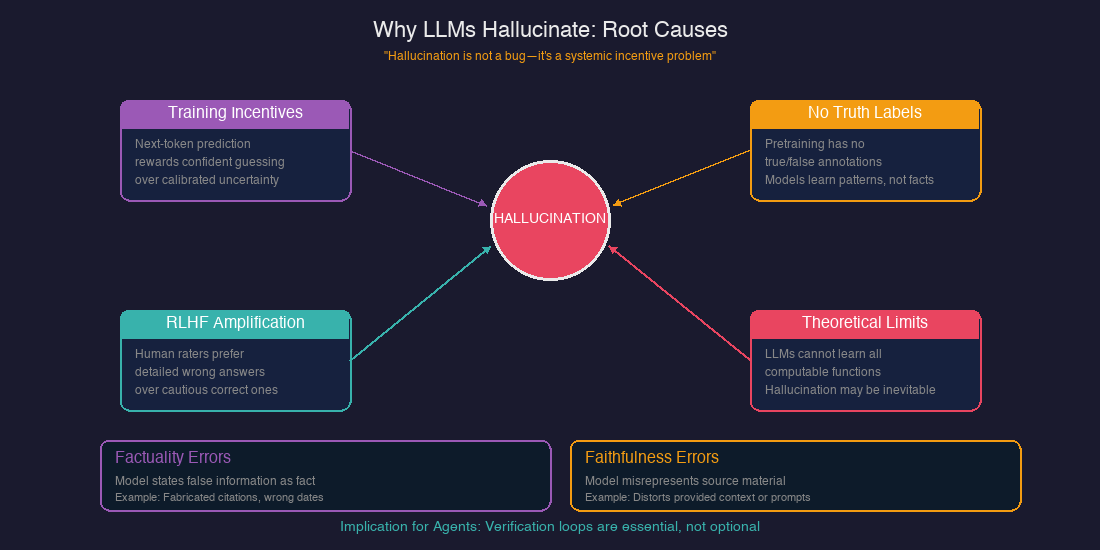
OpenAI's 2025 research identified the core issue: "next-token training objectives and common leaderboards reward confident guessing over calibrated uncertainty." Models learn to bluff because that's what gets rewarded during training.
| Cause | Explanation |
|---|---|
| Training incentives | Models optimize for plausibility, not accuracy. Admitting uncertainty scores poorly on benchmarks. |
| No truth labels | Pretraining data has no "true/false" labels—models learn patterns, not facts. |
| RLHF amplification | Human evaluators often prefer detailed (but wrong) answers over cautious (but correct) ones. |
| Theoretical limits | Recent research suggests LLMs cannot learn all computable functions and will inevitably hallucinate when used as general problem solvers. |
The categories of hallucination I've identified:
- Factuality errors: The model states false information as fact (fabricated citations, wrong dates).
- Faithfulness errors: The model misrepresents or distorts source material provided in context.
A sobering example: in Mata v. Avianca (2023), a lawyer was sanctioned for submitting a court brief containing fabricated case citations generated by ChatGPT.
For agent design, this means verification loops aren't optional—they're fundamental. Anthropic's guidance about the "Gather-Act-Verify" pattern makes more sense now. The "Verify" step exists precisely because the underlying model cannot be trusted to be factually accurate by default.
What I've Learned So Far
After diving into this material, a few things crystallized:
- Transformers process in parallel. Transformers see all tokens at once and use attention to determine relevance. This is why they're fast but memory-intensive.
- Tokenization shapes everything. What the model "sees" is determined by how text is split into tokens. Unusual inputs (code, non-English text, technical jargon) can behave unexpectedly.
- Attention is expensive. The quadratic cost of attention explains why longer contexts come with significant tradeoffs. Just because a model can process 1M tokens doesn't mean it should.
- Context windows have practical limits. Performance degrades past certain thresholds. The "lost in the middle" phenomenon means more context isn't always better.
- Hallucination is structural. It's not a bug to fix—it's a natural property of how these systems are trained. This makes verification essential, not optional.
What's Next
In the next article, I'm diving into Prompt Engineering, exploring zero-shot, few-shot, and chain-of-thought patterns. Understanding how LLMs work helps, but knowing how to talk to them effectively is where the practical skill lives. I want to figure out what makes prompts reliable and predictable.
*This is Article 2 of 12 in my AI Agents learning journey.*