The Skill That Makes or Breaks Your Agent
Introduction
Series: My Journey to Building AI Agents
Audience: Senior Full Stack Developers · Solution Architects · Tech Leads
Here's something that stuck with me from Anthropic's docs: specificity is the single most important lever in effective prompting. Being vague about format, length, or intent forces the model to guess — and it usually guesses wrong.
"Anthropic's documentation emphasizes that specificity is one of the most important factors in effective prompting."
That single line reframed how I think about prompting. It's not about clever tricks, it's about clear communication with a system that takes everything literally.
After digging into how LLMs work in the last article, I realized that understanding the engine is only half the story. The other half is knowing how to steer it. Prompt Engineering is where theory meets practice — it's the interface between what I want and what the model produces. And for agents that run autonomously, getting this right isn't optional.
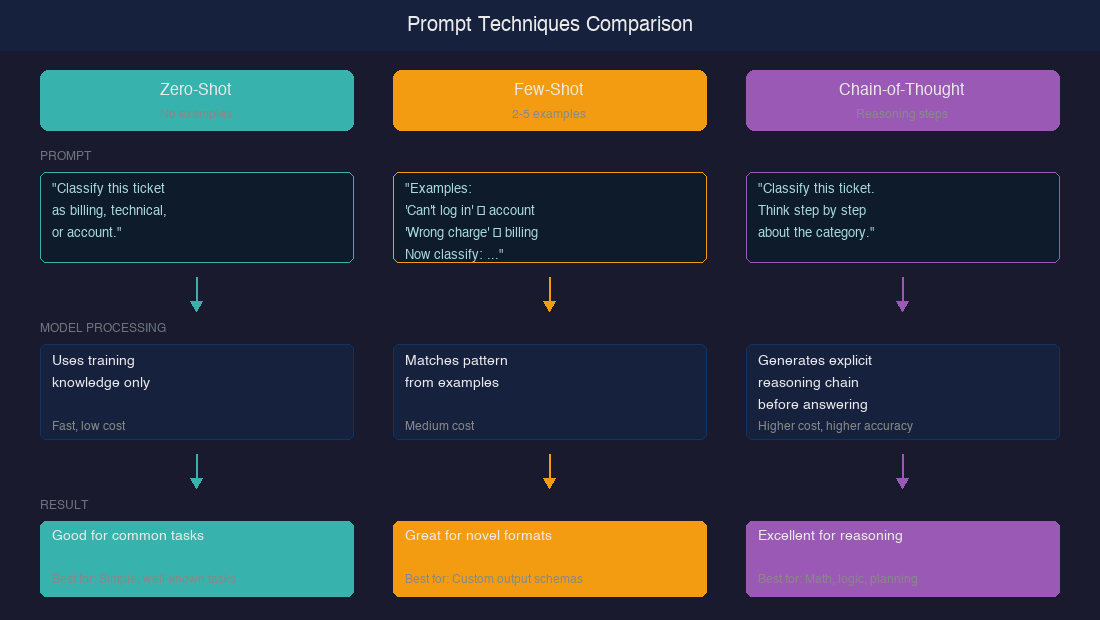
In this article, I'm working through five core techniques: zero-shot, few-shot, chain-of-thought, system prompts, and structured outputs. For each one, I want to understand when it works, when it doesn't, and why it matters for agents. Let's figure this out together.
Zero-Shot Prompting: Start Here
Zero-shot means giving the model an instruction with no examples — just the task description. It sounds simple, but honestly? With modern models like Claude and GPT-4, it works better than I expected.
Anthropic's documentation emphasizes that "Claude responds well to clear, explicit instructions."— specificity in the instruction itself matters more than adding examples.
OpenAI's prompt engineering guide similarly recommends starting with zero-shot, then adding examples only when results are insufficient.
Few-Shot Prompting: Show, Don't Tell
When zero-shot falls short, examples fill the gap. The original GPT-3 paper by Brown et al. (2020) demonstrated that few-shot prompting — providing examples in context — could match or exceed fine-tuned models on several benchmarks.
Anthropic calls this "multishot prompting" and describes it as "one of the most effective ways to improve Claude's performance." Their key advice: provide diverse, relevant examples — and include edge cases.
Here's a comparison that helped me understand the tradeoff
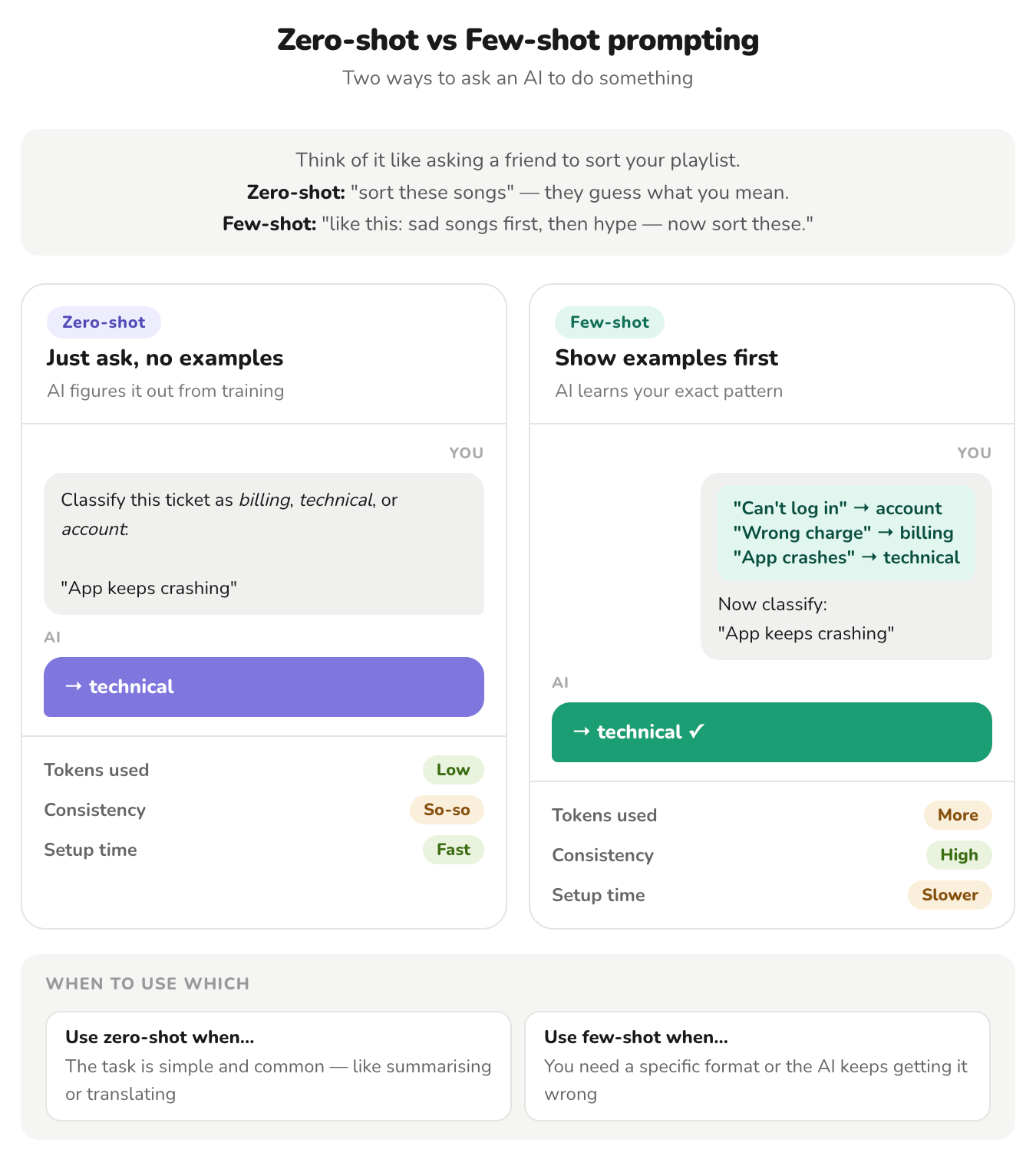
When does zero-shot work?
- Classification
- Summarization
- Translation
- Simple Q&A tasks (model has seen extensively during training)
Where it struggles:
- highly specialized formats
- domain-specific reasoning
- when the desired output structure is ambiguous
For agents, zero-shot has a practical advantage — it keeps token budgets low. In an agentic loop where the prompt gets re-sent every turn, saving tokens on examples compounds quickly.
So how many examples do I actually need?
| Examples | Effect | Research Finding |
|---|---|---|
| 0 | Zero-shot baseline | Relies entirely on training knowledge |
| 1-2 | Format anchoring | Establishes output structure |
| 3-5 | Sweet spot | Captures most performance gains (practitioner consensus; gains taper beyond this range |
| 6-8 | Diminishing returns | Marginal improvement, higher token cost |
| 10+ | Rarely justified | Consumes context window for little gain |
The research consensus: 3-5 diverse examples capture most of the benefit. Quality and diversity matter more than quantity.
Here's what I've found works for agent tool-calling — showing 2-3 examples of correct tool invocation eliminates most format errors:
# Few-shot examples for agent tool selection
examples = [
{
"user": "What's the weather in Tokyo?",
"reasoning": "User needs current weather data — requires API call",
"tool": "get_weather",
"params": {"city": "Tokyo"}
},
{
"user": "Summarize this PDF for me",
"reasoning": "User has a document to analyze — no external API needed",
"tool": "analyze_document",
"params": {"action": "summarize"}
}
]Chain-of-Thought: Let the Model Think
This is the technique that genuinely surprised me with its effectiveness. Chain-of-thought (CoT) prompting asks the model to show its reasoning before giving an answer — and the results are dramatic.
Researchers discovered that AI models get dramatically better at solving problems just by being asked to show their work — like a student who scores way higher on a test when they write out their steps instead of just guessing the answer.
In one study (Wei et al), math problem accuracy on GSM8K jumped from 17% to 56% with chain-of-thought prompting alone — reaching 58% only when also paired with an external calculator. Even wilder (Kojima et al), another study found that adding the phrase "Let's think step by step" to a prompt bumped accuracy from 17.7% to 78.7%. That's five words turning a failing grade into an A.
CHAIN-OF-THOUGHT IN ACTION
════════════════════════════════════════════════════════════════
WITHOUT CoT: WITH CoT:
Q: "A store has 15 apples. Q: "A store has 15 apples.
8 are sold, then 12 arrive. 8 are sold, then 12 arrive.
How many?" How many? Think step by step."
A: "20" ✗ A: "Starting: 15 apples
After sales: 15 - 8 = 7
After delivery: 7 + 12 = 19
Answer: 19" ✓
But here's the nuance that matters: CoT doesn't always help. Wang et al. (2022) Wei et al. (2022) showed it can actually hurt performance on simple tasks — for the easiest single-step problems, CoT improvements were either negative or very small. My mental model:
| Task Complexity | CoT Effect | Example |
|---|---|---|
| Simple recall | Neutral or harmful | "What's the capital of France?" |
| Classification | Minimal benefit | Clear-cut sentiment analysis |
| Multi-step reasoning | Major improvement | Math, logic, planning |
| Complex analysis | Essential | Code debugging, multi-document synthesis |
Anthropic's documentation recommends using chain of thought specifically for "complex tasks that require analysis" and suggests using XML tags like <thinking> to separate reasoning from final answers.
For agent design, this is directly relevant. The ReAct pattern (Yao et al., 2022) — which interleaves "Thought," "Act," and "Observe" steps — is essentially chain-of-thought applied to agents. The agent reasons about which tool to call, executes it, observes the result, then reasons again. Most modern agent frameworks use this as their default pattern.
System Prompts: The Agent's Constitution
If chain-of-thought is how agents reason, system prompts are how they're governed. Anthropic describes the system prompt as defining "Claude's role, personality, and rules", and for agents, it's essentially a constitution.
One technique that stood out: role prompting. Anthropic notes it works best when the role is specific — "a pediatric nurse" rather than just "a nurse." Specificity matters because it activates more relevant training patterns.
Here's how I think about system prompt architecture for agents:
SYSTEM PROMPT ARCHITECTURE
════════════════════════════════════════════════════════════════
┌─────────────────────────────────────────────────────────┐
│ IDENTITY "You are a senior DevOps engineer │
│ specializing in Kubernetes..." │
├─────────────────────────────────────────────────────────┤
│ CAPABILITIES "You have access to these tools: │
│ - kubectl_exec: Run kubectl cmds │
│ - read_logs: Fetch pod logs │
│ - alert_team: Send Slack alerts" │
├─────────────────────────────────────────────────────────┤
│ CONSTRAINTS "NEVER delete resources without │
│ explicit user confirmation. │
│ ALWAYS check pod status before │
│ restarting." │
├─────────────────────────────────────────────────────────┤
│ OUTPUT FORMAT "Respond with a JSON action: │
│ {tool, params, reasoning}" │
└─────────────────────────────────────────────────────────┘The four layers I keep seeing in effective agent system prompts:
- Identity: Who is the agent? What domain expertise does it have?
- Capabilities: What tools/actions are available?
- Constraints: What must the agent never do? What requires confirmation?
- Output format: How should the agent structure its responses?
OpenAI's guidance aligns — they recommend system messages define both what the model should and should not do. For agents running autonomously, the "should not" is arguably more important.
Structured Outputs: Making Agents Parseable
Agents don't just generate text — they generate actions. And actions need to be machine-parseable. This is where structured output techniques become essential.

*This is Article 3 of 12 in my AI Agents learning journey.*
See you there.
Resources I'm Using
- Prompt Engineering Overview — Anthropic
- Multishot Prompting — Anthropic
- Chain of Thought — Anthropic
- System Prompts — Anthropic
- XML Tags — Anthropic
- Prefill Response — Anthropic
- Prompt Engineering Guide — OpenAI
- Structured Outputs — OpenAI
- Chain-of-Thought Prompting — Wei et al., 2022
- Zero-Shot Reasoners — Kojima et al., 2022
- Language Models are Few-Shot Learners — Brown et al., 2020
- ReAct: Reasoning and Acting — Yao et al., 2022
- Self-Consistency — Wang et al., 2022